在数字化时代,数据分析已成为各行各业不可或缺的重要技能。为了深入了解当前市场对数据分析师岗位的需求情况,我们从BOSS直聘平台上爬取了一份关于数据分析师招聘信息的数据集。本博客将通过对这份数据进行可视化分析,揭示数据分析师岗位的地域分布、薪资水平、经验要求、学历要求以及技能标签等关键信息,帮助求职者更好地把握市场动态,制定职业规划。
一、数据集简介 本次分析的数据集包含了以下字段:
二、数据预处理 在正式分析之前,我们加载数据集并进行了预处理,具体流程如下:
2.1 加载分析需要的库 import numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport warningsfrom scipy.stats import norm,modeimport refrom collections import Counterimport pyecharts.options as optsfrom pyecharts.charts import WordCloud'font.sans-serif' ] = ["SimHei" ]'axes.unicode_minus' ] = False 2.2 导入数据 "boss.csv" ,header=None )'company' ,'job_position' ,'job_address' ,'job_salary' ,'job_exper' ,'company_type' ,'tags' ]
2.3 数据清洗
首先把工作job_exper :经验要求及学历,拆分成工作经验experience 和学历diploma 字段;
df["experience" ]=df["job_exper" ].str.extract("^(\d+/?-\d+)" )"diploma" ]=df["job_exper" ].str[-2 :]"experience" ].replace(np.nan,"经验不限" ,inplace=True )"experience" ].replace("1-3" ,"1-3年" ,inplace=True )"experience" ].replace("3-5" ,"3-5年" ,inplace=True )"experience" ].replace("5-10" ,"5-10年" ,inplace=True )"experience" ].unique()def avg_ar (x) :if "-" in x:"-" )return (int(a)+int(b))/2 else :return None "avg_address" ]=df["job_salary" ].apply(lambda x: re.split("K|元" ,x)[0 ])"avg_address" ]=df["avg_address" ].apply(lambda x: avg_ar(x))三、可视化分析 为了进行这些可视化分析,我们将使用Python及其相关库(如pandas、matplotlib、seaborn等)来处理和分析数据。以下是一个详细的步骤指南和相应的Python代码示例。
3.1 各个城市数据分析岗位招聘数量情况 我们可以使用matplotlib或seaborn来绘制各个城市数据分析岗位招聘数量情况。
city_job_num = df['job_address' ].value_counts().reset_index()'city' ,'job_nums' ]'city' , y='job_nums' , data=city_job_num)45 ) '各城市数据分析师招聘数量情况' )南京 发布的数据分析招聘信息数量最多;
3.2 数据分析师在各城市薪资水平情况 我们可以使用matplotlib或seaborn来绘制薪资水平的柱状图。
'job_address' )['avg_address' ].mean().reset_index()'job_address' , y='avg_address' , data=city_salaries)45 ) '数据分析师在各城市薪资水平情况' )北京、杭州、上海、深圳 发布的数据分析招聘信息薪资最高;
3.3 薪资和城市分析 我们已经计算了各城市的在一定范围内的薪资占比情况;
10 ,5 ),dpi=100 )121 )10 ].groupby("job_address" ).avg_address.count()"avg_address" ).iloc[-8 :]"avg_address" ],labels=temp.index,autopct="%.2f%%" )"薪资小于10K的城市占比" )122 )10 ].groupby("job_address" ).avg_address.count()"avg_address" ).iloc[-8 :]"avg_address" ],labels=temp.index,autopct="%.2f%%" )"薪资大于10K的城市占比" )
3.4 热门城市薪资箱线图 我们可以选择几个热门城市,并绘制它们的薪资箱线图。
"avg_address" ]<100 ]"北京" ]["avg_address" ]"上海" ]["avg_address" ]"广州" ]["avg_address" ]"深圳" ]["avg_address" ]"杭州" ]["avg_address" ]12 ,6 ))"北京" ,"上海" ,"广州" ,"深圳" ,"杭州" ],"marker" :"o" ,"markerfacecolor" :"r" ,"color" :"k" },True ,"color" :"k" ,"facecolor" :"#FFFACD" })"#FFFAFA" )0.8 )"主要城市薪资水平箱线图" ,fontsize=15 )"薪资(单位:K)" ,fontsize=12 )从上图中可以看出,几个主要的热门城市发布的招聘信息来看,平均薪资最高的是北京 ,最低的是广州 ,杭州的高工资和低工资都比较多,求职者的可能性更大,发展机遇就好,努力奋斗 ;
3.5 学历与薪资数据分析 我们可以使用条形图来展示不同学历的薪资分布。
"avg_address" ].groupby(df["diploma" ])1 ,len(c)+1 ))"int64" )"int64" )0.4 12 ,5 ))"#eed777" )for i in v],x,width=move,color="#334f65" )0 ,7 )+1.2 15 )0 ,60 ,10 )),fontsize=15 )"均值" ,"中位数" ])"各学历薪资均值及中位数比较图" ,fontsize=16 )"学历" ,fontsize=12 )"薪资(单位:K)" ,fontsize=12 )for e,f in zip(v,w):1 ,"{}K" .format(f),ha="center" ,fontsize=12 )for g,h in zip([i+move for i in v],x):1 ,"{}K" .format(h),ha="center" ,fontsize=12 )兄弟们,不说了写好卷学历去了 。
3.6 学历与岗位需求的数据分析 我们可以使用饼状图来展示不同学历在岗位需求中的占比。
"diploma" ].value_counts()6 ,6 ))"%.2f%%" )
3.7 工龄与薪资数据分析 我们可以使用条状图来展示不同工龄的薪资分布。
"avg_address" ].groupby(df["experience" ])1 ,len(c)+1 ))"int64" )"int64" )0.4 14 ,8 ))"#002c53" )for i in v],x,width=move,color="#0c84c6" )0 ,4 )+1.2 15 )0 ,35 ,5 )),fontsize=15 )"均值" ,"中位数" ])"各学历薪资均值及中位数比较图" ,fontsize=16 )"工作经验" ,fontsize=12 )"薪资(单位:K)" ,fontsize=12 )for e,f in zip(v,w):1 ,"{}K" .format(f),ha="center" ,fontsize=12 )for g,h in zip([i+move for i in v],x):1 ,"{}K" .format(h),ha="center" ,fontsize=12 )从图中可以看出,工作的年限越长,工资也会相应的高一些。
3.8 工龄与市场需求分析 我们可以使用饼状图来展示不同工龄在市场需求中的占比。
"experience" ].value_counts()6 ,6 ))"%.2f%%" ,colors = ['tomato' , 'lightskyblue' , 'goldenrod' , 'green' ])
3.9 数据分析岗技能需求情况 tag = df['tags' ].tolist()for item in tag:',' )for item in element_counts.keys():"数据分析岗位技能需求" , 6 , 66 ])"数据分析岗位技能需求" , title_textstyle_opts=opts.TextStyleOpts(font_size=23 )True ),"basic_wordcloud.html" )从上图可以看出,SQL、Python等数据分析工具是基础技能,数据挖掘、大数据处理、建模等高级技能是加分项。
四、结论与建议 通过对BOSS直聘平台上数据分析师招聘信息的可视化分析,我们得出以下结论:
数据分析师岗位主要集中在一线城市和新一线城市,薪资水平较高但竞争激烈。 市场对数据分析师的经验和学历要求以本科为主,但高级岗位对学历和经验要求更高。 SQL、Python等数据分析工具是基础技能,机器学习、大数据处理等高级技能是加分项。
针对以上结论,我们提出以下建议:
求职者应结合自身实际情况,选择适合自己的城市和行业方向。 注重提升个人技能和经验积累,尤其是SQL、Python等数据分析工具的使用能力。 关注市场动态和新兴技术趋势,不断拓展自己的知识边界和技能组合。



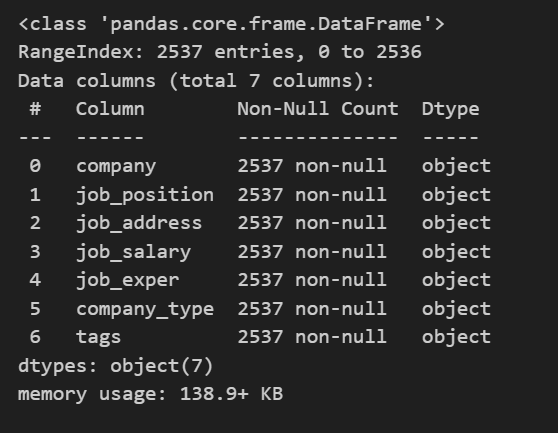 数据一共有7个维度,2537条招聘记录,而且数据中无缺失值的存在。
数据一共有7个维度,2537条招聘记录,而且数据中无缺失值的存在。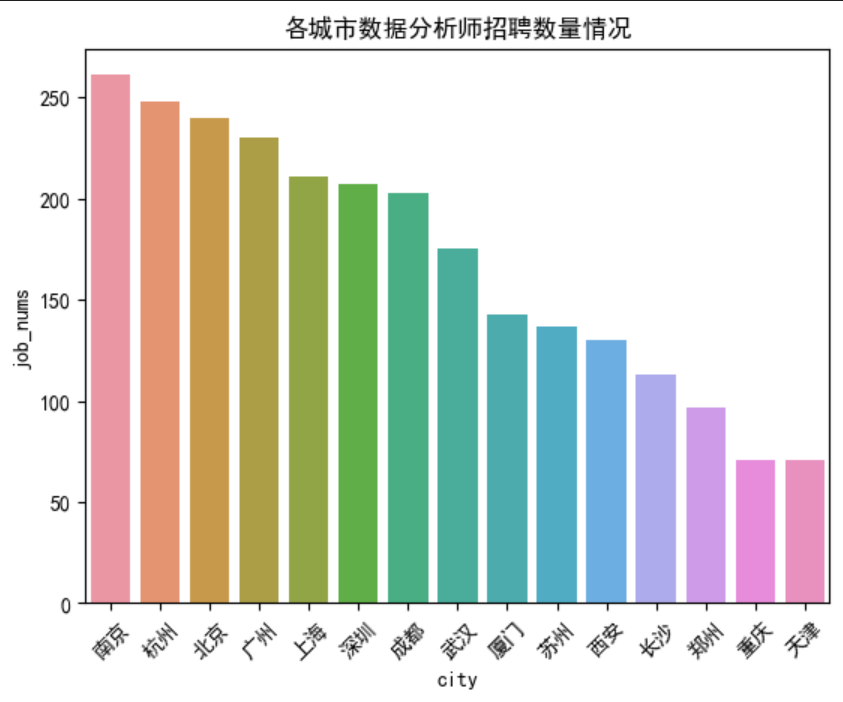 从图中我们可以知道,南京发布的数据分析招聘信息数量最多;
从图中我们可以知道,南京发布的数据分析招聘信息数量最多;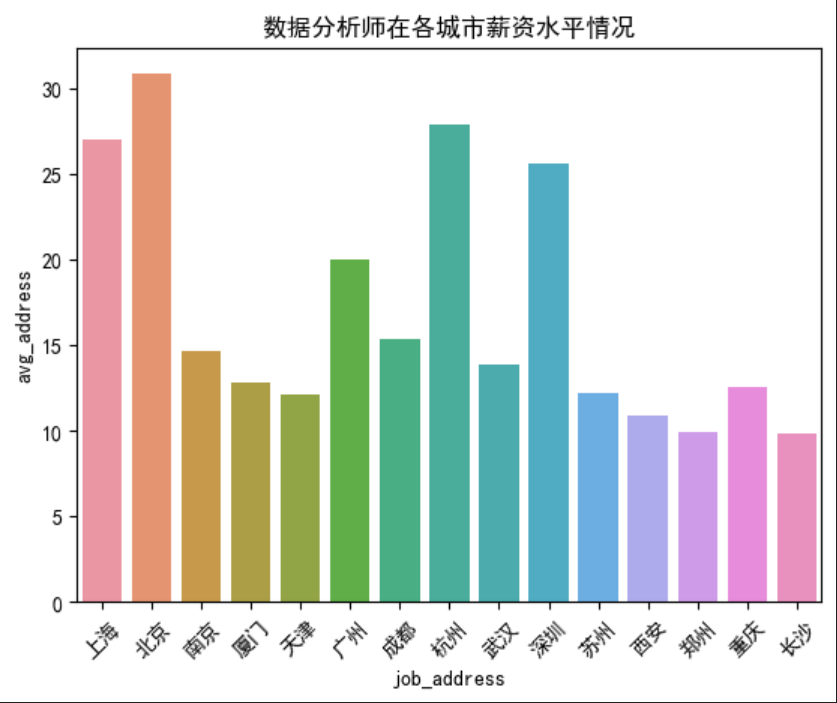 从图中我们可以知道,北京、杭州、上海、深圳发布的数据分析招聘信息薪资最高;
从图中我们可以知道,北京、杭州、上海、深圳发布的数据分析招聘信息薪资最高;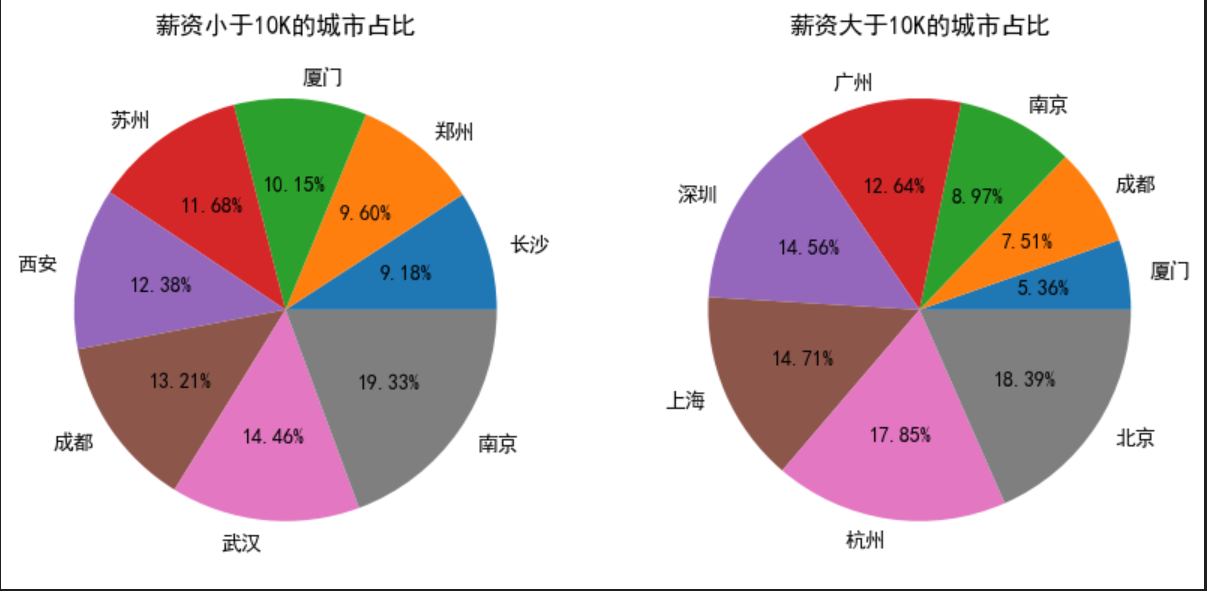 从上图可以看出,在薪资小于10k的城市占比中南京和武汉发布的招聘最高,在薪资大于10k的城市占比中北京和杭州发布的招聘信息最多。
从上图可以看出,在薪资小于10k的城市占比中南京和武汉发布的招聘最高,在薪资大于10k的城市占比中北京和杭州发布的招聘信息最多。
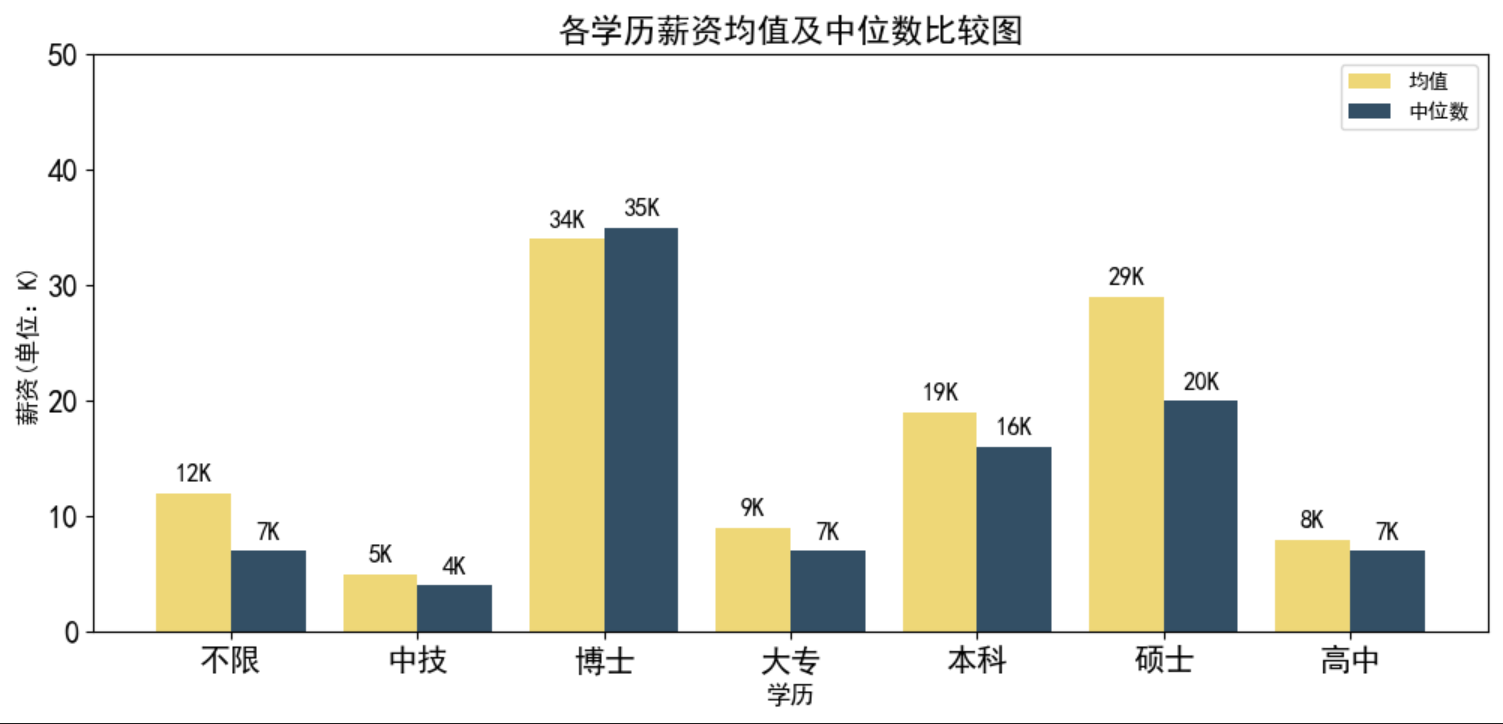 从上图可以看得出,薪资和学历一般是呈现正相关的关系,学历越高薪资也会越高,兄弟们,不说了写好卷学历去了。
从上图可以看得出,薪资和学历一般是呈现正相关的关系,学历越高薪资也会越高,兄弟们,不说了写好卷学历去了。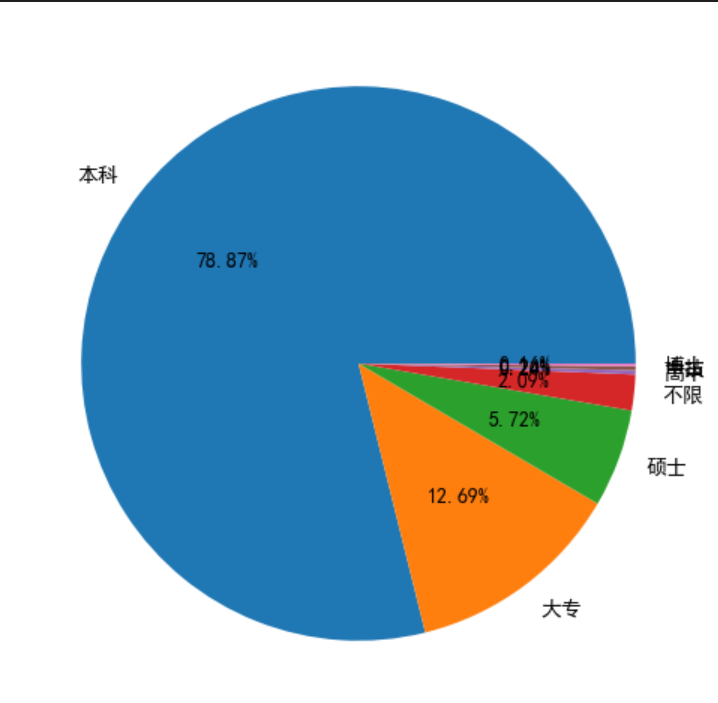 从上图可以看出,数据分析岗位招聘要求中本科学历是占绝大多数的。
从上图可以看出,数据分析岗位招聘要求中本科学历是占绝大多数的。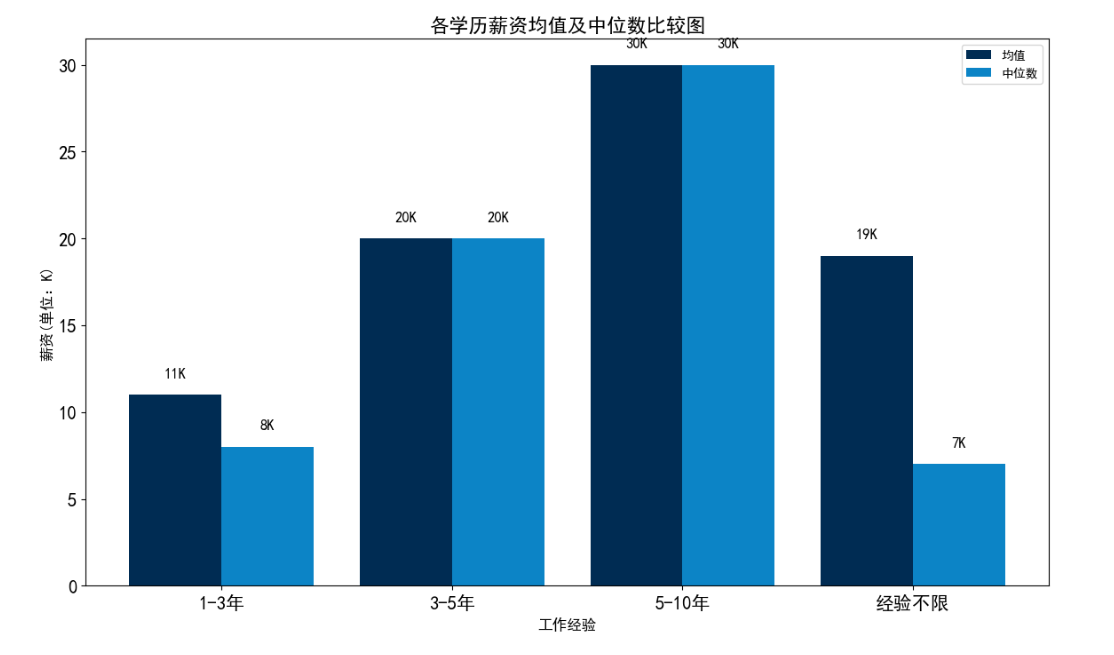
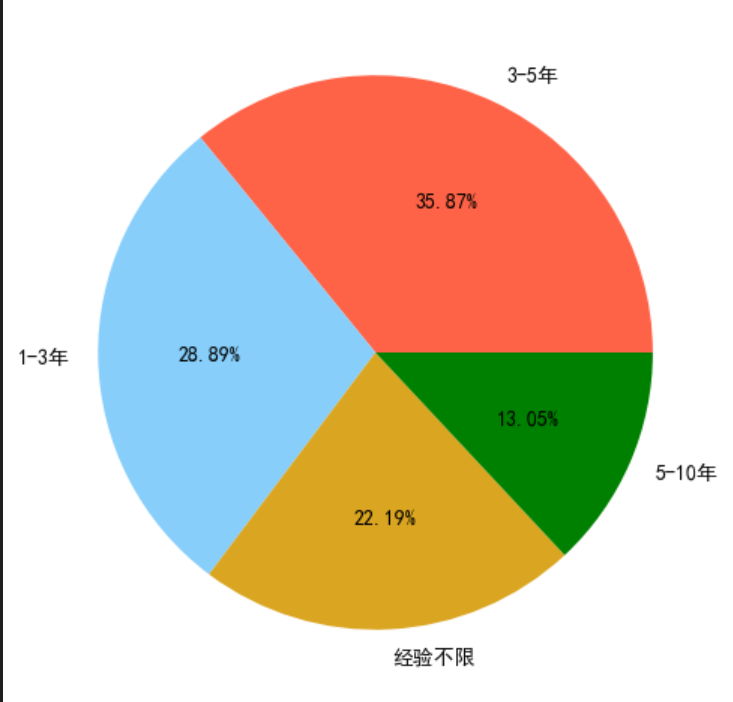 从上图可以看出,工龄3-5年工作的人有一定的工作经验,工资也相对较小,所以比较受欢迎。的需求量是最大的占35.87%,该3-5年工作的人有一定的工作经验,工资也相对较小,所以比较受欢迎。
从上图可以看出,工龄3-5年工作的人有一定的工作经验,工资也相对较小,所以比较受欢迎。的需求量是最大的占35.87%,该3-5年工作的人有一定的工作经验,工资也相对较小,所以比较受欢迎。